Алексей Левин, Экоцентр МТЭА
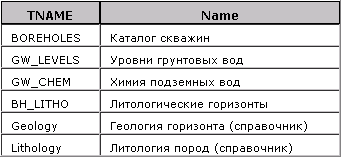
Многие разработчики реляционных БД применяют собственные наборы системных таблиц TABLES (список таблиц), COLUMNS (список атрибутов), DATATYPES (типы данных) и т.п. Такие описания структуры, выполненные в табличной же форме, называют еще «метаданными». В качестве примера приведем небольшую БД мониторинга грунтовых вод, список таблиц которой приводится в примере 1.
Пример 1. Метатаблица TABLES
Метаданные содержат, как правило, кроме чисто системных, еще и вспомогательные, пользовательские параметры: заголовок таблицы, заголовки атрибутов, единицы измерения и другие. Метаданные применяются обычно для построения интерфейса, однако их структурная роль не менее важна.
Следует отметить, что в последние годы в публикациях и разработках, особенно на тему геоинформационных систем (ГИС), под метаданными понимаются только вспомогательные, справочные сведения, данные о происхождении данных. Такое сужение термина вряд ли имеет смысл, так как приставка «мета-» во всех областях знаний имеет устоявшийся смысл «сверх-». Термином «сверх-данные» можно с полным правом именовать любые данные более высокого уровня, любые «данные о данных», а не только справочно-реферативные. В данной статье термин «метаданные» применяется именно в таком широком смысле. В первую очередь, однако, речь пойдет о системных данных.
Общим для метаданных разных разработчиков, как правило, является отказ от описания связей в виде отдельной таблицы (REFERENCES/CONSTRAINTS «больших» СУБД). Действительно, для описания простой структуры она не является необходимой. Например, в схеме С. А. Виноградова хорошо показано, как можно обойтись без REFERENCES, описывая связь как свойство атрибута в таблице COLUMNS [1]. Для атрибута исходной таблицы (источника), являющегося внешним ключом (foreign key) указывается ссылка на целевую таблицу. Со стороны целевой таблицы, само собой разумеется, связь опирается всегда только первичный ключ (Primary Key). При необходимости нетрудно создать запросом представление REFERENCES, включающее обычные для таких представлений колонки Source.Table, Source.Column, Target.Table, Target.Column и тип связи — «один-к-одному» или «один-ко-многим». В таком варианте схема, разумеется, ограничивает связи одинарными.
Вряд ли возможно описать составные связи, не выделяя сущность «связь» в отдельную таблицу. Но так ли уж связи необходимы именно составные? Практика свидетельствует, что не сложно обойтись и без них. В последнее время все шире применяется принцип построения системы на одинарных связях, использующих искусственные первичные ключи (ИК) [2]. Как правило, ИК имеют целочисленный тип, и популярны благодаря механизму уникальной автонумерации. С помощью ИК действительно удается построить систему практически любой сложности.
Однако естественный ключ, тем не менее, сохраняет свое значение и жизненно важен для любой таблицы, как средство контроля соответствия данных предметной области. Набор естественных ключей должен быть взаимоувязан, тогда он образует каркас системы, обеспечивая естественный порядок и поддерживая «предметную» целостность в дополнение к чисто «логической». Если система не замкнута, то есть активно общается с предметной областью, постоянно получает новые данные, то только естественный ключ поможет правильно их идентифицировать. Поскольку роль первичного ключа, как правило, занимает ИК, то естественный ключ таблицы должен быть реализован как уникальный индекс. В связи с этим далее для него применяется сокращение «ЕИ». По идее К. Дейта [3] и ИК и ЕИ — потенциальные ключи, равноправные с точки зрения таблицы. С точки зрения системы ИК «назначен» первичным для простоты организации связей.
Описание ЕИ должно присутствовать именно в метаданных, если система претендует на соответствие реляционной модели. Это практически не усложняет схему. В простом варианте ЕИ может быть одинарным, но обычно строки в таблице идентифицируются однозначно только по набору атрибутов. Такой набор обычно называется составным (или композитным) ключом (уникальным индексом). Описать составной ЕИ несложно, если условиться, что в таблице он будет один. Можно предназначить для этого логическую колонку СUnique в таблице атрибутов ATTRIBUTES, и определить, что все помеченные атрибуты в пределах одной таблицы составляют ЕИ этой таблицы (далее колонки таблицы ATTRIBUTES называются просто «колонками», во избежание путаницы между атрибутами метаданных и атрибутами основной БД).
Пример 2. Метатаблица ATTRIBUTES.
Приведены
основные атрибуты трех таблиц. ИК показан только для BOREHOLES.
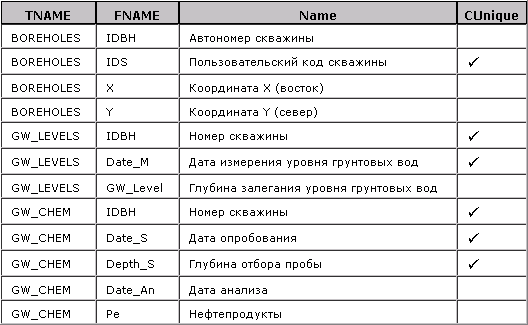
Для таблицы BOREHOLES, например, ЕИ — одинарный, это «Пользовательский код скважины». Для таблицы GW_LEVELS ЕИ составной, включает два атрибута — «Номер скважины» и «Дату измерения уровня грунтовых вод». Для GW_CHEM — в ЕИ добавляется еще и «Глубина отбора пробы». Для правильного формирования таблицы ЕИ является крайне важным. Именно его значения «воплощает» ИК при связи с BOREHOLES.
Еще раз подчеркнем, что смысл колонки СUnique принципиально иной, чем указание уникальности одного атрибута. Это «принадлежность атрибута к составному естественному уникальному индексу». Уникальность одного атрибута (при наличии ИК и ЕИ) представляется несущественной для большинства задач. В случае необходимости нетрудно добавить в ATTRIBUTES колонку Unique именно с таким смыслом. Однако мы предпочитаем для системных характеристик отдельно взятого атрибута иметь колонку Status (с возможными значениями «not null», «unique», «archive» и т.п.). Впрочем, это дело вкуса.
В любой системе полезно иметь в метаданных колонку Name для краткого текстового заголовка атрибута, колонку Units для единиц измерения, Info — для детальных пояснений. Для параметров мониторинга имеет смысл пополнить метаданные специфической информацией: возможно добавление колонки CAS (номер вещества по международной системе), колонки MPC — «Предельно Допустимая Концентрация» или другой нормативный показатель для параметра, колонок Max и Min, хранящих допустимый числовой диапазон, метода измерения, нижнего предела метода и т.п. Разумеется, при обилии справочных колонок структура метаданных потребует нормализации, и обычно это приводит к возникновению отдельных таблиц PARAMETERS, UNITS, списка методов наблюдений METHODS, справочника нормативных документов DOCUMENTS и т.п. Таблица параметров содержит измеряемые/наблюдаемые параметры мониторинга и некоторые другие числовые показатели (как правило, все числовые атрибуты БД, за исключением ключевых). В ходе дальнейшего развития каждая таблица обрастает дочерними, и образует целую ветвь. Например, для полноценной работы с единицами измерения мы применяем систему из шести таблиц — «Элементарные единицы измерения», «Приставки к единицам измерения» и т.п. Полное описание структур такого рода, впрочем, несколько выходит за рамки статьи.
Такая схема, как и все аналогичные, позволяет пользовательским приложениям «знать» структуру БД, получать автоматически необходимую метаинформацию. При наличии таких метаданных не является проблемой оперативное документирование системы. Приложения могут строить упрощенный пользовательский интерфейс полностью автоматически, «на лету», что немаловажно для публикации данных средствами интернета. Кроме того, для задач мониторинга становится возможным оперативный контроль качества данных, автоматический пересчет в удобные единицы измерения, пересчет в иные размерности (например, доли ПДК), обработка /корректировка пропущенных значений и многое другое.
Пример 3. Метатаблица ATTRIBUTES.
Приведены все
атрибуты двух таблиц.
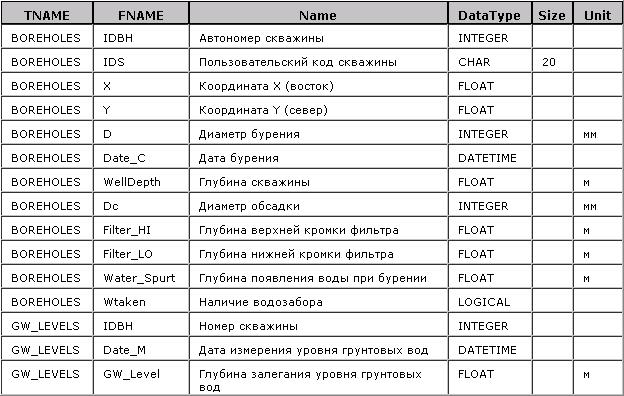
Однако в такой схеме очевидна избыточность — например, для атрибутов «номер скважины» тип данных указывается каждый раз, хотя они явно должны быть одинаковы. Однотипными должны быть и все даты, все диаметры, все глубины. Единицы измерения и даже допустимый диапазон для таких атрибутов тоже должны совпадать (в контексте данной предметной области).
Поэтому есть смысл нормализовать структуру, группируя общие свойства атрибутов в отдельной таблице. Получившиеся сущности представляют собой пользовательские типы данных, что близко по смыслу к понятию домен, поэтому таблица именуется DOMAINS. Метаданные становятся заметно компактнее. Соответствие типов данных связуемых полей гарантировано.
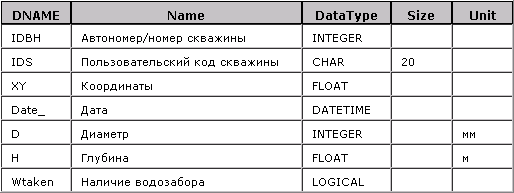
Пример 4. Метатаблица DOMAINS
Приведены домены,
соответствующие атрибутам примера 2.
При создании доменов нужно руководствоваться здравым смыслом и пониманием предметной области, помня о том, что в атрибутах, «приписанных» к одному домену, согласно классике реляционной модели данных, разрешено любое сопоставление – сложение, вычитание, другие алгебраические операции. Если это не желательно хотя бы потенциально, то лучше не относить атрибуты к одному домену, как бы они ни казались похожими – и по типу данных, и по единицам измерения. Например, вряд ли стоит относить к одному домену содержания кальция и меди. Напротив, различные сопоставления содержаний кальция и магния имеют смысл, и они могут быть приписаны к единому домену. Отметим, что имя домена должно быть уникальным в пределах всей БД. Каждый атрибут должен принадлежать какому-либо домену, и только одному домену.
В то же время список доменов никак не должен быть слепком списка атрибутов. Например, разумно отнести все глубины по скважинам к одному домену, включая глубину установки фильтра. Тогда в системе явно фиксируется возможность сопоставлений глубины появления воды и глубины установки фильтра, глубины отбора пробы и глубины грунтовых вод, что значительно расширяет возможности проведения проверок, анализов. Оперативно контролировать образование доменов удобно с помощью списка пар совместимых атрибутов. Список пар реализуется соединением ATTRIBUTES-DOMAINS-ATTRIBUTES. Если список возможных пар покажется слишком широким, можно исключить некоторые атрибуты из домена, разбить домен на части, перевести атрибуты в другой близкий по смыслу домен.
После организации работы с доменами в системе ограничивается количество возможных сравнений. Если строго следовать реляционной модели, сравнения возможны только значений — атрибутов одного домена. При преведении сравнений и построении связей все операции должны обращаться к доменам, а не к типам данных. Однако функциональность системы при этом не страдает, наоборот, повышается. Доменная организация как бы надстраивает обычную схему БД, основанной на внешних ключах, предлагая альтернативные смысловые («доменные») связи для любой операции. Другими словами, этот подход позволяет фиксировать в системе «потенциальные» связи, и это настолько же органично для систем мониторинга, как и «потенциальные» первичные ключи. То же, видимо, можно сказать и о любой БД в естественной отрасли.
В СУБД «Метадата» Е.Ноздри, созданной для геологических данных (в разработке которой принимал участие и автор статьи), внешние ключи вообще были отменены, заменены альтернативными связями через домены. Такой подход уменьшал детерминированность баз данных, и открывал ряд интересных возможностей. Однако, это заставляло искусственно сужать список атрибутов в каждом домене, с тем чтобы сократить список потенциальных связей до минимума. Как следствие, список доменов в базах данных обычно был ненамного короче, чем список атрибутов. Вряд ли разумно идти на такие крайности в общем случае.
Доменная организация метаданных позволяет добиться улучшения взаимодействия системы с пользователем (в широком смысле слова). Типовым приемом является предложение пользователю списка потенциальных связей для выбора как вариантов при построении связей в запросах, как возможных путей навигации по таблицам, для подгрузки альтернативных справочников и т.п.
Представляется удобным хранить для каждого домена и способы представления «пропущенных значений». Раньше, как многие помнят, приходилось кодировать значения NULL кодами типа -1, -9999, -32 768, «null», «-», «не известно» и тому подобное. Ныне в большинстве современных СУБД есть способы явного указания значения NULL (Unknown). Однако по-прежнему нет способов указания N/A (not available, не свойственно), что представляется необходимым для всех систем [4]. Для целей мониторинга важным также является указание «ниже предела измерения» (Parameters.BelowLimit в примере 3). Оно, кстати говоря, эквивалентно указанию «следы» (traces), популярному в геологических БД. При этом реальное значение самого параметра обычно не фиксируется измерениями и не регистрируется в БД либо игнорируется, а при обработке интерпретируется различными способами, в зависимости от задач. Для моделирования фона, например, применяется подстановка половины нижнего предела метода (наиболее вероятное значение), для задач оценки загрязнения подстановка нижнего предела (максимально возможное). Если типы пропуска значения не указывать, то в БД мониторинга каждый параметр придется сопровождать серией логических колонок-флагов. Очевидно, что наличие в системе таких указаний обязывает все обращения к данным выполнять строго сквозь метаданные, для предварительной обработки пропущенных значений и значений ниже предела. Это, по сути, порождает еще один уровень представления данных, что добавляет работы программистам.
Пример 5. Схема метаданных БД мониторинга (упрощенная).
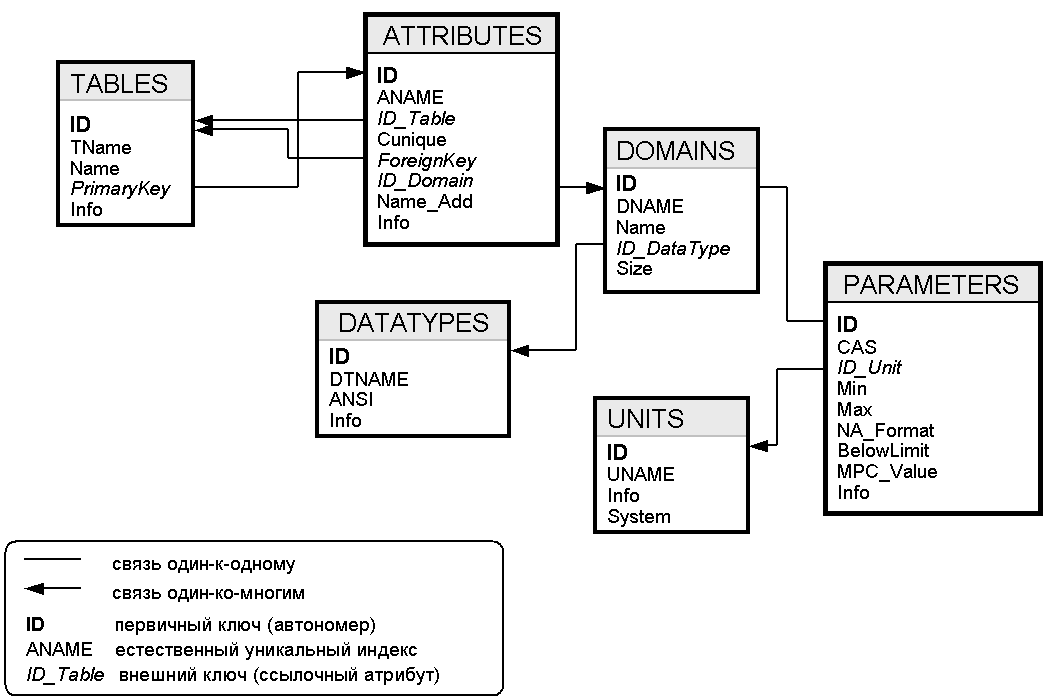
Итак, схема с доменами работает, описывает одинарные связи между таблицами, хранит составные ЕИ и способна выдавать по запросу все необходимые системные представления, как и предыдущие описанные. Кроме этого, в явном виде указана принадлежность атрибутов доменам, что позволяет учитывать совместимость при любых операциях. Это позволяет проводить осмысленный анализ данных, повышает соответствие предметной области. C системных позиций также важно иметь полный список совместимых пар, как кандидатов на установление альтернативных связей между таблицами, как основу операций реляционной алгебры типа UNION/JOIN/INTERSECTION, чтобы последние имели не только чисто математический, но и предметный смысл. Нормализовано хранение типов данных, что позволяет стройно развивать метаданные мониторинга параллельно с ходом проекта и усложнением понимания предметной области.
Большое спасибо Е. Ноздре за многие из мыслей и их реализацию
в СУБД «Метадата». Н. Терскому за возможность обсудить и реализовать многие
аспекты совместными усилиями, в ходе работ по проектам мониторинга. С.
Виноградову за терпеливые разъяснения своих идей, что позволило
усовершенствовать схему, а также за предоставленную возможность опубликовать эту
статью.
Любые замечания будут приняты с вниманием по адресу: geologic@pisem.net